
Artificial intelligence continues to advance rapidly, and one of the most intriguing developments is CriticGPT. This tool is designed to enhance the capabilities of large language models (LLMs). by acting as a critic to help detect and rectify errors. CriticGPT leverages reinforcement learning from human feedback (RLHF) to improve the accuracy and reliability of AI-generated content, particularly in coding tasks.
The Need for CriticGPT
As AI models become more sophisticated, evaluating their outputs becomes increasingly challenging for humans. Traditional RLHF methods rely heavily on human judgment to assess the quality of AI outputs, but this approach has limitations. Humans are not always able to identify subtle or complex errors in AI-generated content, especially as models grow more advanced. This gap in evaluation can lead to the propagation of errors and biases, potentially resulting in unsafe or flawed AI systems.
CriticGPT addresses this issue by providing a scalable oversight mechanism. It helps humans accurately assess AI-generated outputs, particularly in coding tasks where precise error detection is crucial. By acting as an automated critic, CriticGPT enhances the reliability of AI systems and reduces the burden on human evaluators.
How CriticGPT Works
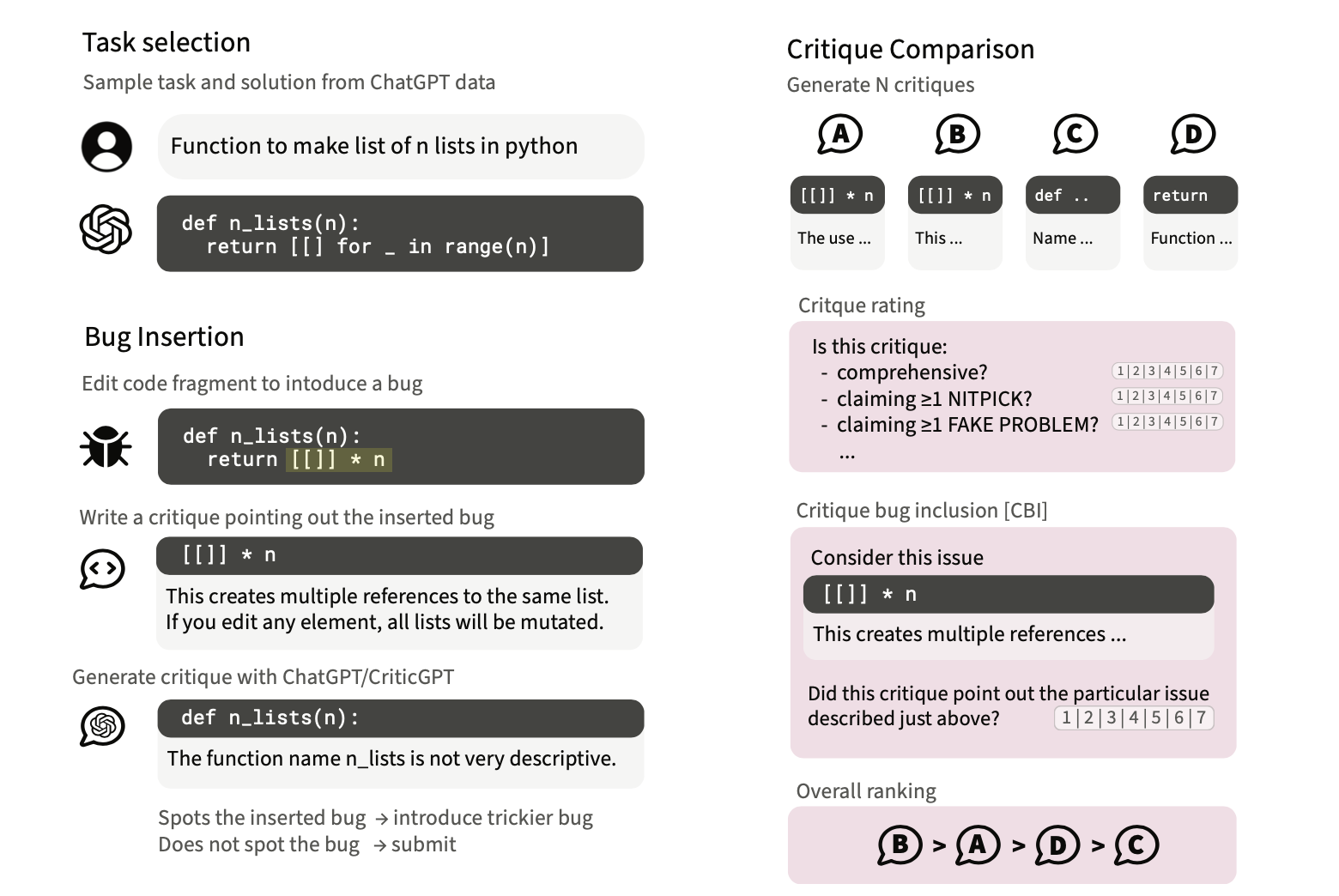
CriticGPT is based on the GPT-4 architecture and is fine-tuned using RLHF. The training process involves several steps:
- Data Collection: A large dataset of coding tasks and their corresponding solutions is collected. This dataset includes both human-generated and AI-generated content.
- Bug Insertion: Human contractors intentionally insert subtle bugs into the code to create challenging evaluation scenarios. These bugs are designed to test the critic’s ability to detect and highlight errors that might be missed by human reviewers.
- Critique Generation: CriticGPT generates critiques for the given coding tasks. These critiques are detailed feedback highlighting potential errors and providing suggestions for improvement.
- Evaluation and Fine-Tuning: The generated critiques are evaluated by human contractors, who rate their accuracy and helpfulness. This feedback is used to fine-tune CriticGPT, improving its ability to detect and correct errors over time.
Evaluating CriticGPT
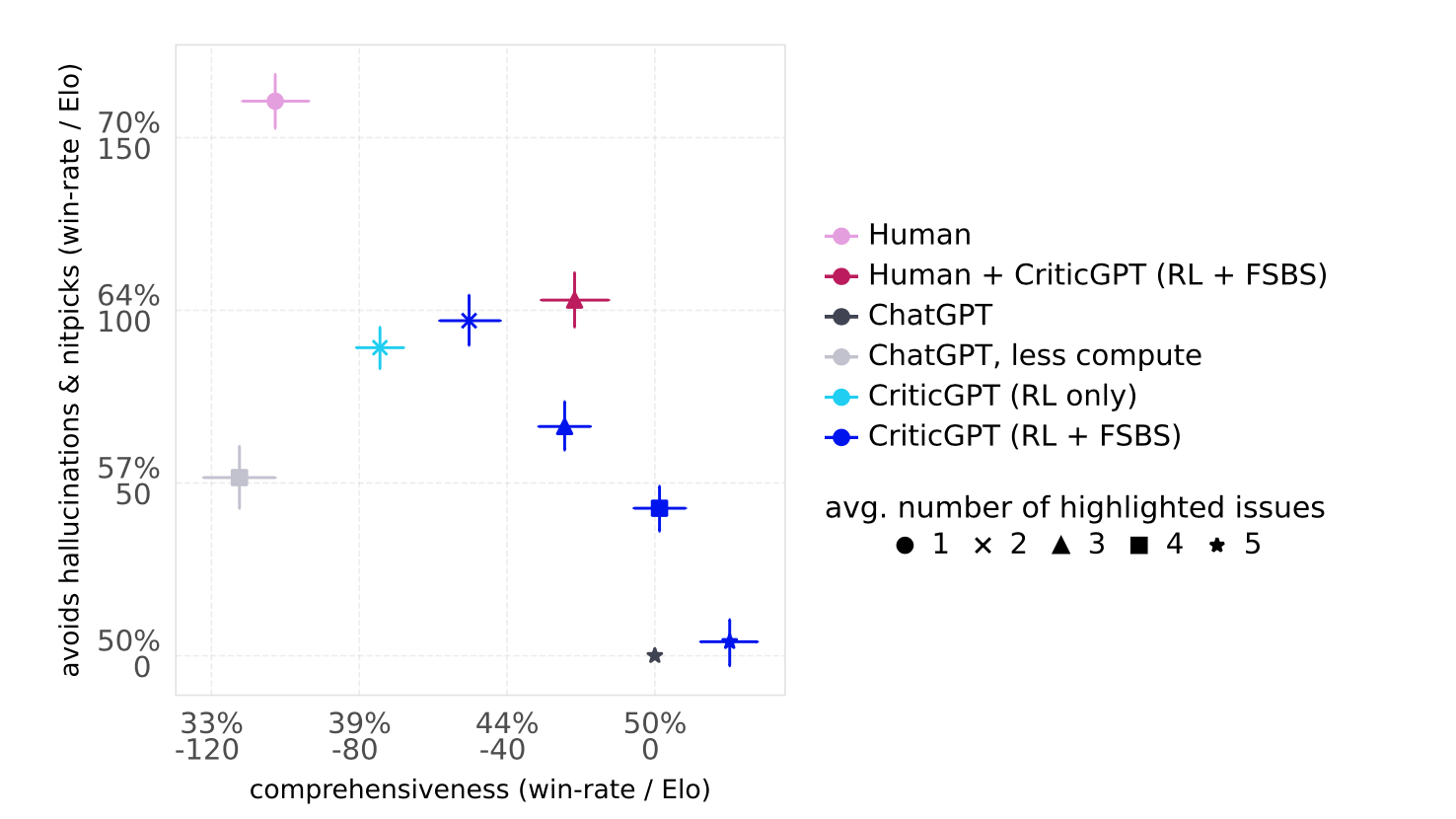
CriticGPT’s effectiveness is evaluated through a series of rigorous tests. These tests compare the performance of CriticGPT to human reviewers and other AI models. Key evaluation metrics include:
- Comprehensiveness: The ability of CriticGPT to identify all significant errors in a given piece of code.
- Critique-Bug Inclusion (CBI): The rate at which CriticGPT includes specific, pre-identified bugs in its critiques.
- Hallucinations and Nitpicks: The tendency of CriticGPT to introduce non-existent errors (hallucinations) or overly minor issues (nitpicks) in its critiques.
- Overall Helpfulness: A subjective rating of how useful CriticGPT’s feedback is to human reviewers.
Key Findings
The results of these evaluations have been promising. CriticGPT consistently outperforms human reviewers in identifying errors in AI-generated code. In tests, CriticGPT’s critiques were preferred over human critiques in 63% of cases. Additionally, human-machine teams (consisting of human reviewers assisted by CriticGPT) caught more bugs than either humans or CriticGPT alone.

(b) Contractors prefer CriticGPT (RL only) over prompted ChatGPT across model scales on Human Inserted Bugs. CriticGPT (RL only) misses inserted bugs less often than ChatGPT. Training a larger model also reduces the rate of missed inserted bugs. However, to match the performance of CriticGPT (RL only) on this distribution, one would need around a 30x increase in pre-training compute.
One notable finding is that CriticGPT is particularly effective at identifying errors that humans might overlook. For instance, in a set of coding tasks where human contractors inserted bugs, CriticGPT was able to detect a significant portion of these errors, even when human reviewers could not. This capability highlights the potential of CriticGPT to enhance the reliability of AI systems by providing a higher level of scrutiny.
Benefits of CriticGPT
CriticGPT offers several key benefits:
- Increased Accuracy: By catching errors that humans might miss, CriticGPT improves the overall accuracy of AI-generated content.
- Scalable Oversight: CriticGPT provides a scalable solution for overseeing AI outputs, reducing the reliance on human reviewers and enabling more comprehensive evaluations.
- Enhanced Reliability: The use of CriticGPT in AI development pipelines helps ensure that AI systems are more reliable and trustworthy, particularly in critical applications like coding.
Limitations and Challenges
While CriticGPT has demonstrated impressive capabilities, it is not without limitations. One challenge is the potential for hallucinated bugs, where CriticGPT incorrectly identifies non-existent errors. These false positives can mislead human reviewers and complicate the evaluation process.
Another limitation is the scope of CriticGPT’s training. The model is primarily trained on coding tasks, which means its effectiveness in other domains may be limited. Extending CriticGPT’s capabilities to a broader range of tasks requires additional training and evaluation.
Future Directions
The development of CriticGPT represents a significant step forward in scalable oversight for AI systems. However, there are several avenues for further improvement:
- Broader Training: Expanding the training dataset to include a wider variety of tasks can enhance CriticGPT’s versatility and effectiveness in different domains.
- Interactive Feedback: Developing interactive feedback mechanisms where CriticGPT can engage in a dialogue with human reviewers to clarify and refine its critiques.
- Reduced Hallucinations: Refining the training process to minimize the occurrence of hallucinated bugs and improve the precision of CriticGPT’s critiques.
Conclusion
CriticGPT is a powerful tool that enhances the accuracy and reliability of AI systems by providing scalable oversight for AI-generated content. Its ability to detect errors that humans might miss and its consistent performance in evaluations make it a valuable addition to the AI development pipeline. As AI continues to evolve, tools like CriticGPT will play a crucial role in ensuring that these systems are safe, reliable, and trustworthy.
Read related articles: