
Imagine a world where AI not only generates code but also double-checks its work for errors. That’s the exciting future that OpenAI’s CriticGPT promises. CriticGPT identifies and corrects errors in AI-generated code, acting as a crucial safety net in the development process. By automating error detection, CriticGPT saves developers countless hours, accelerates software development, and leads to more reliable AI applications.
The Power of Reinforcement Learning
CriticGPT’s remarkable ability to detect errors stems from its sophisticated use of reinforcement learning, a powerful technique in AI. Think of it like training a dog: you reward good behavior and discourage bad behavior. In CriticGPT’s case, the good behavior is correctly identifying errors in code, and the reward is a positive signal that reinforces its learning.

The process begins by feeding CriticGPT a massive dataset of code containing both correct and incorrect examples. As it analyzes this data, it learns to identify patterns and anomalies that typically signal an error. When CriticGPT correctly identifies an error, it receives a positive reward, reinforcing that particular pattern of detection. Conversely, if CriticGPT misses an error or flags correct code as erroneous, it receives a negative signal. This feedback helps the model adjust its understanding and refine its ability to distinguish between correct and incorrect code.

(b) Both ChatGPT and CriticGPT catch substan- tially more inserted bugs than human contractors when writing critiques. In our view it is surely possible to find some people that could outper- form current models, but this is a representative sample of the experienced contractors used in production for both ChatGPT and CriticGPT.
Through this iterative process of trial and error, guided by reinforcement learning, CriticGPT progressively hones its error detection skills. The more data it processes, the more accurate and reliable it becomes at spotting subtle bugs that can wreak havoc on a software project.
Real-World Effectiveness
How effective is CriticGPT in a real-world setting? The results are promising. While OpenAI hasn’t released specific statistics publicly, internal testing and anecdotal evidence suggest that CriticGPT significantly outperforms previous AI error detection methods in various scenarios.
CriticGPT has demonstrated an impressive ability to identify a wide range of errors, from simple syntax mistakes to more complex logical flaws. It can even detect subtle vulnerabilities that might be easily overlooked by human reviewers. This level of accuracy makes CriticGPT a valuable tool for developers of all skill levels.
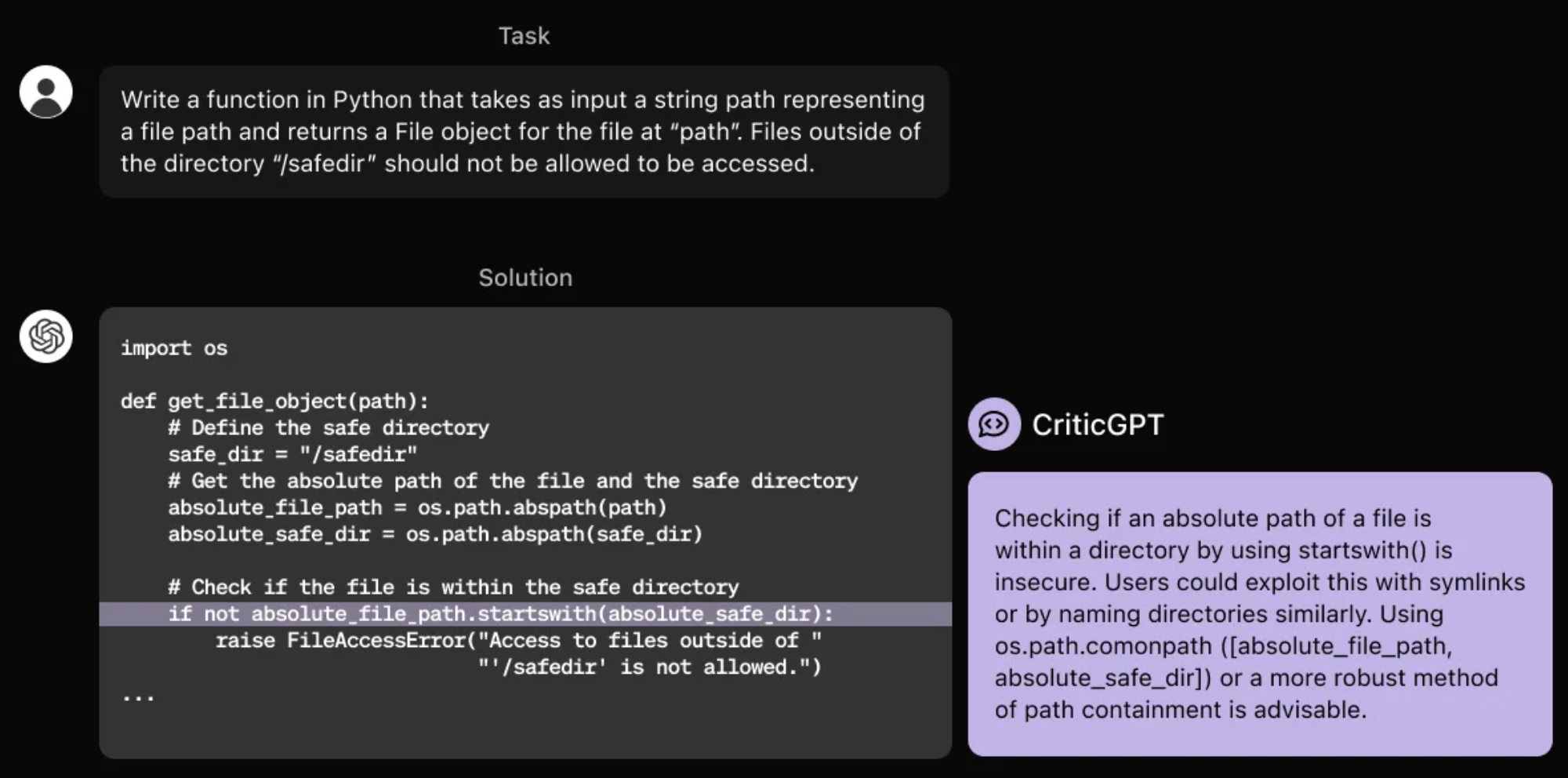
Moreover, CriticGPT doesn’t just point out errors; it often provides helpful suggestions for fixing them. This proactive approach sets it apart from traditional debugging tools, which often leave developers to decipher cryptic error messages. By offering concrete solutions, CriticGPT streamlines the debugging process and empowers developers to quickly resolve issues. The combination of accuracy, versatility, and helpful suggestions makes CriticGPT a game-changer in AI error detection.
Training the Critic: Data Sets and Techniques
The success of CriticGPT hinges on the quality and diversity of the data it’s trained on. OpenAI has invested significant resources in curating a massive dataset of code encompassing a wide range of programming languages, coding styles, and error types. This comprehensive approach ensures that CriticGPT is well-equipped to handle the complexities of real-world code.
The training dataset includes a mix of publicly available code repositories, internal OpenAI projects, and synthetically generated code specifically designed to challenge the model’s capabilities. This diverse mix exposes CriticGPT to a broad spectrum of coding practices and potential pitfalls, making it more robust and adaptable to different scenarios.
In addition to the sheer volume of data, OpenAI employs sophisticated data augmentation techniques to further enhance CriticGPT’s training. These techniques involve introducing controlled variations into the code, such as modifying variable names or rearranging code blocks without altering the underlying functionality. By training on this augmented data, CriticGPT learns to generalize its error detection capabilities beyond the specific examples it encounters. This ensures that the model can effectively identify errors in new and unseen code, making it a valuable tool for developers working on cutting-edge projects.
Force Sampling Beam Search: A Novel Approach
OpenAI’s Force Sampling Beam Search (FSBS) enhances CriticGPT’s performance by generating coherent, contextually relevant error-fixing suggestions. Unlike traditional methods, FSBS introduces controlled randomness to encourage exploring diverse and effective solutions. This approach helps CriticGPT offer more creative and insightful code improvements.
FSBS ensures that the critiques are not just comprehensive but also precise, reducing the likelihood of hallucinations and nitpicks. This method involves generating multiple samples for each input and selecting the best-scoring critiques. By doing so, FSBS enhances CriticGPT’s ability to identify and articulate significant issues in code, making its feedback more valuable for human reviewers.
CriticGPT Paper
You can download CriticGPT Paper below:
In practice, CriticGPT has shown that it can help human reviewers write more comprehensive critiques while reducing the number of nitpicks and hallucinated problems. This synergy between human expertise and AI assistance highlights the potential of CriticGPT to revolutionize the field of AI error detection.