The OpenAI API offers a variety of models, each with unique capabilities and pricing options. Additionally, you can customize these models for specific applications through fine-tuning.
OpenAI Flagship models:
MODEL DESCRIPTIONS
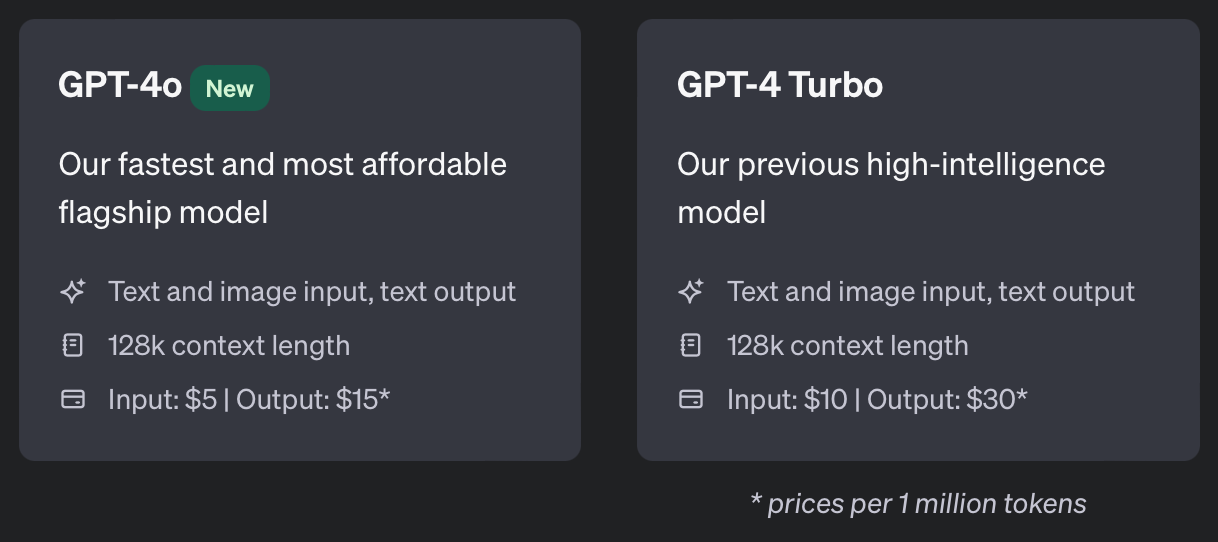
- GPT-4o: The fastest and most cost-effective flagship model.
- GPT-4 Turbo and GPT-4: Previous high-intelligence models.
- GPT-3.5 Turbo: A quick, budget-friendly model for simple tasks.
- GPT Base: Models without instruction-following capabilities that can understand and generate natural language or code.
- CriticGPT: an advanced AI model that provides detailed critiques to enhance the accuracy and reliability of AI-generated content, particularly in coding tasks, by identifying and correcting errors.
Continuous Model Upgrades
Models such as GPT-4o, GPT-4 Turbo, GPT-4, and GPT-3.5 Turbo always point to their latest versions. You can verify the specific version used by checking the response object after sending a request, which will include the model version (e.g., gpt-3.5-turbo-1106).
OpenAI also provide pinned model versions that developers can use for at least three months after a new model version is released. With their new model update cadence, we’re offering the opportunity for people to contribute evaluations (evals) to help improve the models for various use cases. If you’re interested in contributing, please visit the OpenAI Evals repository.
GPT-4o
GPT-4o (“o” for “omni”) is our most advanced model, offering multimodal capabilities (accepting text or image inputs and outputting text). It matches the high intelligence of GPT-4 Turbo but is significantly more efficient, generating text twice as fast and at half the cost. GPT-4o excels in vision and non-English language performance. Available through the OpenAI API for paying customers. Learn more in our text generation guide.
| MODEL | DESCRIPTION | CONTEXT WINDOW | TRAINING DATA |
|---|---|---|---|
| gpt-4o | Our most advanced, multimodal flagship model, cheaper and faster than GPT-4 Turbo. Points to gpt-4o-2024-05-13. | 128,000 tokens | Up to Oct 2023 |
| gpt-4o-2024-05-13 | The current version of GPT-4o. Points to gpt-4o-2024-05-13. | 128,000 tokens | Up to Oct 2023 |
GPT-4 Turbo and GPT-4
GPT-4 is a large multimodal model (accepting text or image inputs and outputting text) capable of solving complex problems with greater accuracy due to its extensive general knowledge and advanced reasoning abilities. Optimized for chat but also effective for traditional completion tasks using the Chat Completions API. Available to paying customers via the OpenAI API. Learn more in our text generation guide.
| MODEL | DESCRIPTION | CONTEXT WINDOW | TRAINING DATA |
|---|---|---|---|
| gpt-4-turbo | The latest GPT-4 Turbo model with vision capabilities, supporting JSON mode and function calling. Points to gpt-4-turbo-2024-04-09. | 128,000 tokens | Up to Dec 2023 |
| gpt-4-turbo-2024-04-09 | GPT-4 Turbo with Vision model. Supports JSON mode and function calling. Points to gpt-4-turbo-2024-04-09. | 128,000 tokens | Up to Dec 2023 |
| gpt-4-turbo-preview | GPT-4 Turbo preview model. Points to gpt-4-0125-preview. | 128,000 tokens | Up to Dec 2023 |
| gpt-4-0125-preview | GPT-4 Turbo preview model intended to reduce cases of “laziness” where the model doesn’t complete a task. Returns up to 4,096 output tokens. | 128,000 tokens | Up to Dec 2023 |
| gpt-4-1106-preview | GPT-4 Turbo preview model with improved instruction following, JSON mode, reproducible outputs, parallel function calling. Returns up to 4,096 output tokens. | 128,000 tokens | Up to Apr 2023 |
| gpt-4 | Currently points to gpt-4-0613. | 8,192 tokens | Up to Sep 2021 |
| gpt-4-0613 | Snapshot of GPT-4 from June 13th, 2023 with improved function calling support. | 8,192 tokens | Up to Sep 2021 |
| gpt-4-0314 | Legacy snapshot of GPT-4 from March 14th, 2023. | 8,192 tokens | Up to Sep 2021 |
GPT-4 excels in complex reasoning and multilingual capabilities, outperforming previous models and most state-of-the-art systems as of 2023.
GPT-3.5 Turbo
GPT-3.5 Turbo models can understand and generate natural language or code, optimized for chat but also effective for non-chat tasks using the Chat Completions API.
| MODEL | DESCRIPTION | CONTEXT WINDOW | TRAINING DATA |
|---|---|---|---|
| gpt-3.5-turbo-0125 | The latest GPT-3.5 Turbo model with higher accuracy in responding to requested formats and fixed text encoding issues for non-English language function calls. Returns up to 4,096 output tokens. | 16,385 tokens | Up to Sep 2021 |
| gpt-3.5-turbo | Currently points to gpt-3.5-turbo-0125. | 16,385 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-1106 | GPT-3.5 Turbo model with improved instruction following, JSON mode, reproducible outputs, parallel function calling. Returns up to 4,096 output tokens. | 16,385 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-instruct | Similar capabilities as GPT-3 era models. Compatible with legacy Completions endpoint and not Chat Completions. | 4,096 tokens | Up to Sep 2021 |
GPT Base
GPT base models can understand and generate natural language or code but are not trained with instruction following. These models are intended to replace our original GPT-3 base models and utilize the legacy Completions API. Most customers should opt for GPT-3.5 or GPT-4.
| MODEL | DESCRIPTION | MAX TOKENS | TRAINING DATA |
|---|---|---|---|
| babbage-002 | Replacement for the GPT-3 ada and babbage base models. | 16,384 tokens | Up to Sep 2021 |
| davinci-002 | Replacement for the GPT-3 curie and davinci base models. | 16,384 tokens | Up to Sep 2021 |
CriticGPT
CriticGPT is an advanced large language model developed to provide detailed critiques and improve the accuracy of AI-generated content, especially in coding tasks. It leverages reinforcement learning from human feedback (RLHF) to detect and highlight errors that might be missed by human reviewers, thus offering a scalable oversight mechanism.
By generating comprehensive critiques, CriticGPT helps enhance the reliability and safety of AI systems, making it a valuable tool in the AI development pipeline. Its effectiveness has been demonstrated in various evaluations, showing that it consistently outperforms human reviewers and other AI models in error detection and critique generation.